MQ官网文档:
RabbitMQ:https://www.rabbitmq.com/docs
RocketMQ:https://rocketmq.apache.org/zh/docs/
Kafka:https://kafka.apache.org/documentation/
DDMQ:https://base.xiaojukeji.com/docs/ddmq
面试题:分布式消息中间件 MQ
- 一、消息队列 MQ
- 1. 消息队列有哪些应用场景 ?
- 2. 引入消息队列会带来哪些问题 ?
- 3. 如何选择合适的消息队列 ?
- 4. 消息队列有哪些,以及各自的特点 ?
- 5. 如何避免消息被重复消费 ?
- 6. 如何保证消息消费的有序性?
- 7. 如何避免消息堆积 ?
- 二、RabbitMQ
- 1.RabbitMQ 如何确保消息不丢失 ?
- 三、RocketMQ
- 1. RocketMQ 如何保证高可用性 ?
- 2. RocketMQ 的存储机制
- 3. RocketMQ 性能比较高的原因 ?
- 三、Kafka
一、消息队列 MQ
1. 消息队列有哪些应用场景 ?
-
应用解耦:
提升容错性和可维护性。如下图所示:假设有系统B、C、D都需要系统A的数据,系统A调用三个方法发送数据到B、C、D。这时,系统D不需要了,那就需要在系统A把相关的代码删掉。假设这时有个新的系统E需要数据,这时系统A又要增加调用系统E的代码。为了降低这种强耦合,就可以使用MQ,系统A只需要把数据发送到MQ,其他系统如果需要数据,则从MQ中获取即可。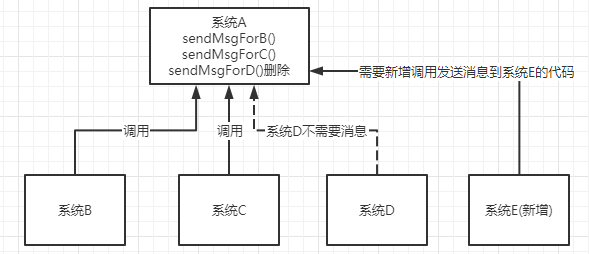
-
异步提速,
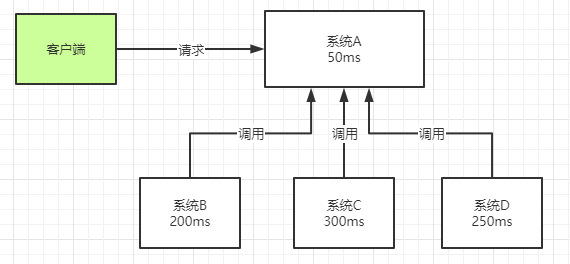
提升用户体验和系统吞吐量(单位时间内处理请求的数目)。如下图所示:一个客户端请求发送进来,系统A会调用系统B、C、D三个系统,同步请求的话,响应时间就是系统A、B、C、D的总和,也就是800ms。如果使用MQ,系统A发送数据到MQ,然后就可以返回响应给客户端,不需要再等待系统B、C、D的响应,可以大大地提高性能。对于一些非必要的业务,比如发送短信,发送邮件等等,就可以采用MQ。
-
削峰填谷,
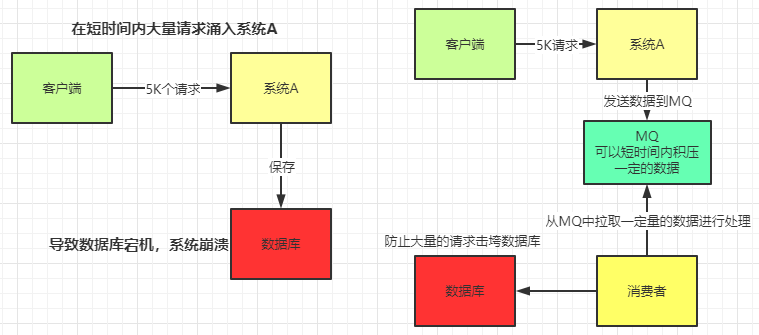
提高系统稳定性。如下图所示:这其实是MQ一个很重要的应用。假设系统A在某一段时间请求数暴增,有5000个请求发送过来,系统A这时就会发送5000条SQL进入MySQL进行执行,MySQL对于如此庞大的请求当然处理不过来,MySQL就会崩溃,导致系统瘫痪。如果使用MQ,系统A不再是直接发送SQL到数据库,而是把数据发送到MQ,MQ短时间积压数据是可以接受的,然后由消费者每次拉取1000条进行处理,防止在请求峰值时期大量的请求直接发送到MySQL导致系统崩溃。
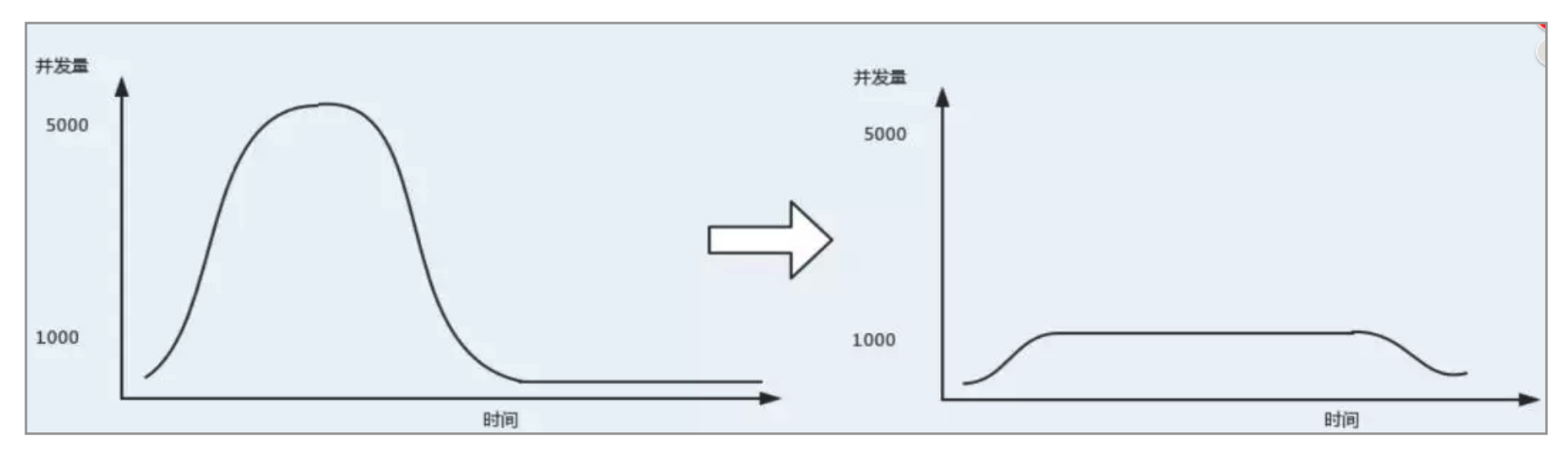
使用了 MQ 之后,限制消费消息的速度为1000,这样一来,高峰期产生的数据势必会被积压在 MQ 中,高峰就被“削”掉了,但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000,直到消费完积压的消息,这就叫做“填谷”
-
延时队列:基于RabbitMQ的死信队列或者DelayExchange插件,可以实现消息发送后,延迟接收的效果
-
保证数据一致性:解决RPC调用失败从而降级,导致的数据不一致问题。让RPC调用改为MQ异步调用,消息在下游服务故障时堆积起来,等故障恢复后再慢慢处理,减少人工接入的成本
2. 引入消息队列会带来哪些问题 ?
-
系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦 MQ 宕机,就会对业务造成影响。如何保证MQ的高可用? -
系统复杂度提高
MQ 的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过 MQ 进行异步调用。如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性? -
一致性问题
A 系统处理完业务,通过 MQ 给B、C、D三个系统发消息数据,如果 B 系统、C 系统处理成功,D 系统处理失败。如何保证消息数据处理的一致性?
3. 如何选择合适的消息队列 ?
一般而言,不同的MQ解决方案在以下方面可能存在差异:
- 性能:包括
吞吐量、延迟、并发处理能力等。不同的MQ系统在处理大量消息和高并发请求时,其性能表现可能有所不同。 - 可靠性:消息队列的
可靠性是评估其性能的重要指标之一。这包括消息的持久化、消息传递的可靠性、故障恢复能力等方面。 - 功能特性:不同的MQ系统可能提供不同的功能特性,如支持的
消息类型、消息传递模式、消息过滤、消息优先级等。 - 集成与扩展性:MQ系统的
集成性和扩展性也是重要的考虑因素。系统是否能够轻松集成到现有的技术栈中,以及是否支持水平扩展以满足不断增长的需求,都是需要考虑的问题。
需要根据不同业务需求,与各种消息队列产品的特点,做出选择。
4. 消息队列有哪些,以及各自的特点 ?
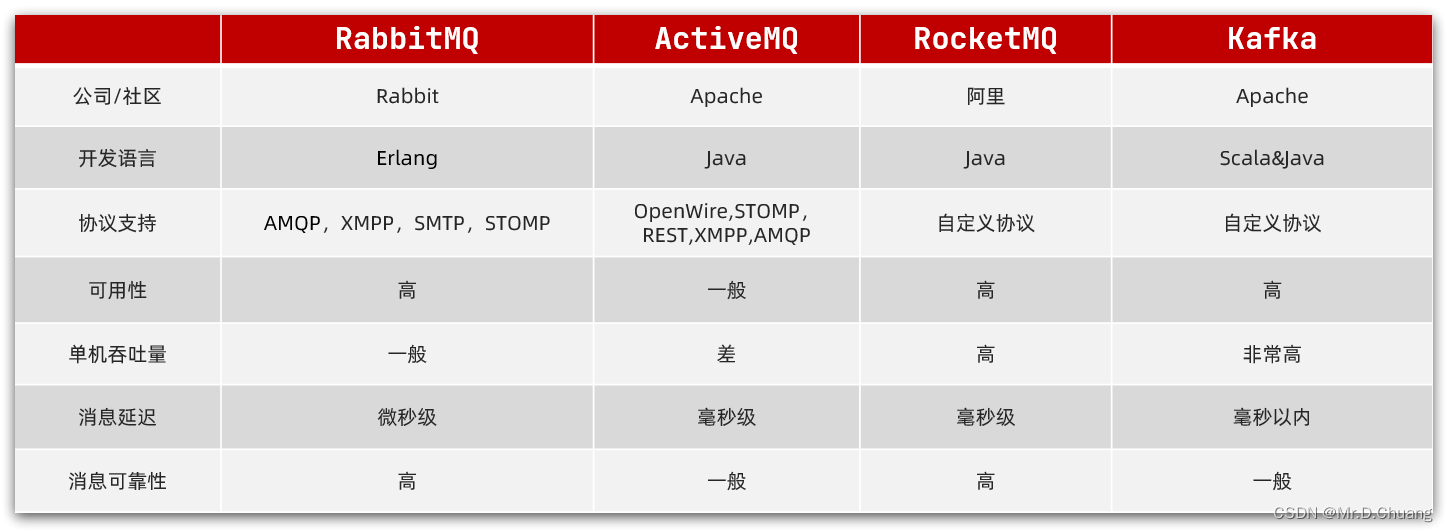
MQ(消息队列)是分布式系统中常用的组件,用于实现 异步通信、系统解耦、流量削峰 等功能。市面上有多种MQ产品,他们各自有特点和适用场景。常见的消息队列中间件包括Kafka、RabbitMQ、ActiveMQ和RocketMQ等。
- RabbitMQ
- 特性:基于Erlang语言开发,支持多种协议(比如AMQP、SMTP)。提供了
可靠性、持久性、分布式和易用性等特点(单机12000吞吐量) - 优点:功能丰富,性能稳定。社区支持活跃。适合中小型软件公司使用
- 缺点:在高并发场景下,可能会面临性能挑战
- 特性:基于Erlang语言开发,支持多种协议(比如AMQP、SMTP)。提供了
- Kafka
- 特性:基于Scala语言开发。支持自定义协议。是一个
分布式、高吞吐量的流处理平台,用于构建实时数据管道和流应用程序。(单机100万吞吐量) - 优点:可以处理海量数据,具有
高吞吐量和低延迟特点。适用于大数据和日志收集场景 - 缺点:
数据稳定性一般,且无法保障消息有序性。复杂性相对较高,需要一定技术知识与配置。此外,它更偏向于数据流处理,而不是简单的消息队列
- 特性:基于Scala语言开发。支持自定义协议。是一个
- RocketMQ
- 特性:基于Java语言开发,支持自定义协议。是一个
高性能、高可用的消息队列服务(单机10万吞吐量) - 优点:对于
消息可靠性有较高要求的场景下是首选。具有强大事务支持、消息回溯等功能 - 缺点:某些方面可能不如RabbitMQ和Kafka功能丰富,且社区支持相对较弱。仅支持Java
- 特性:基于Java语言开发,支持自定义协议。是一个
- ActiveMQ
- 特性:基于Java语言开发,支持多种协议(比如AMQP、SMTP)。(单机6000吞吐量)
- 优点:功能全面,稳定性较好,适用于多种场景
- 缺点:在某些方面可能不如其他MQ产品性能优越,在处理大量消息时可能面临性能挑战。缺乏大规模应用,一般不推荐
5. 如何避免消息被重复消费 ?
消费者消费消息时采用幂等性方案。
生产者给每一条消息添加唯一ID,消费者根据此ID做幂等性保障
以下展示了采用 分布式锁+持久层数据检查 方案,解决串行、并行的重复请求带来的幂等性问题
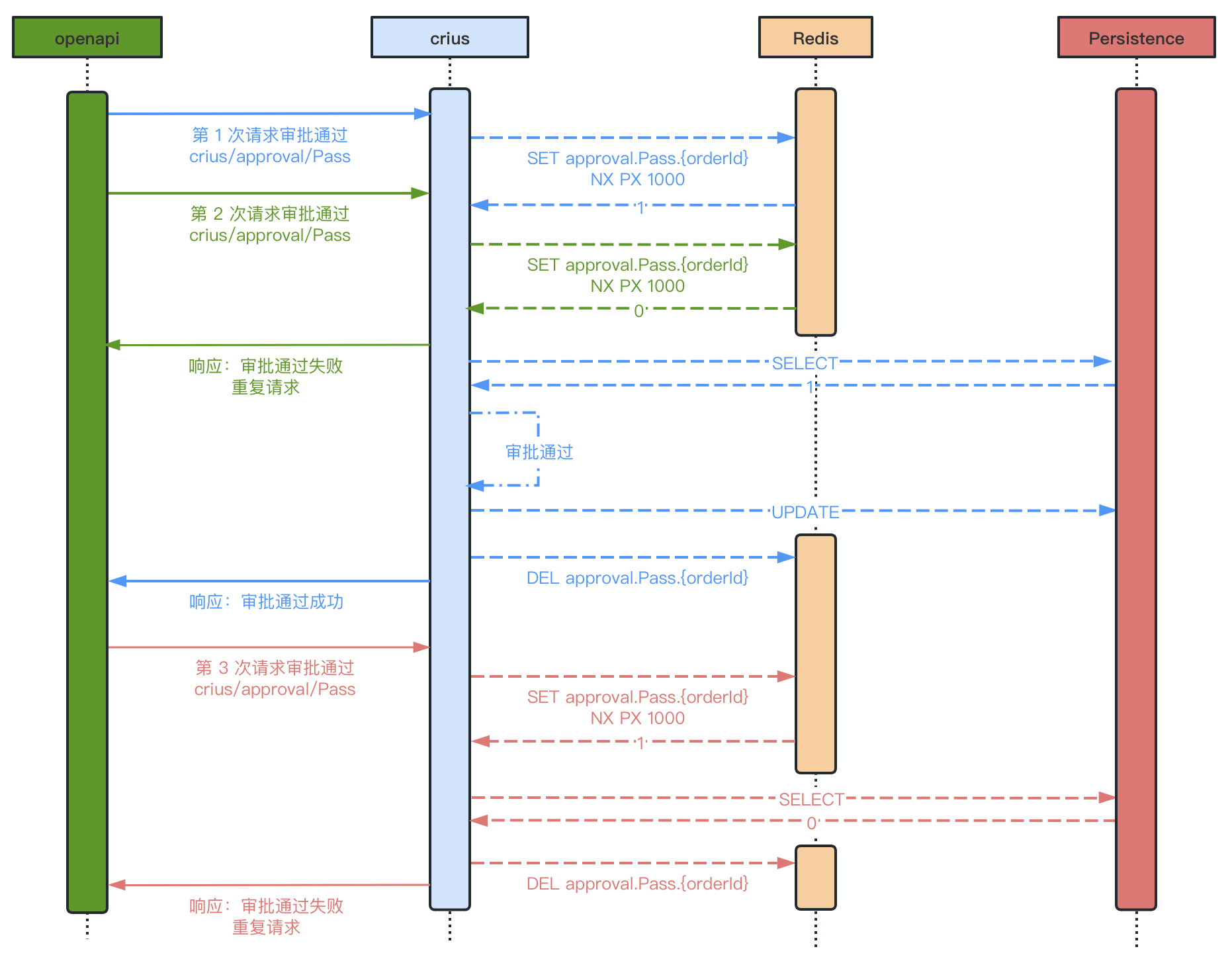
6. 如何保证消息消费的有序性?
其实队列天然具备先进先出的特点,只要消息的发送是有序的,那么理论上接收也是有序的。
不过当一个队列绑定了多个消费者时,可能出现消息轮询投递给消费者的情况,而消费者的处理顺序就无法保证了。
因此,要保证消息的有序性,需要做到以下几点:
- 保证消息发送的有序性
- 保证一组有序的消息都发送到同一个队列
- 保证一个队列只包含一个消费者
7. 如何避免消息堆积 ?
消息堆积问题的产生原因:消息生产速度 > 消息消费速度。
解决方案:
-
提高消费者处理速度。优化消费者业务代码,提高性能
-
增加更多消费者。一个队列绑定多个消费者,共同争抢消息
-
增加消息队列存储上限。RabbitMQ的1.8版本后,引入了新的队列模式:
Lazy Queue
该队列模式不会将消息保存在内存,而是在收到消息后直接写入磁盘,理论上无存储上限
二、RabbitMQ
1.RabbitMQ 如何确保消息不丢失 ?
RabbitMQ针对消息传递过程中可能发生问题的各个地方,给出了针对性的解决方案:
- 生产者发送消息时可能因为网络问题导致
消息没有到达交换机:- RabbitMQ提供了
publisher confirm机制- 生产者发送消息后,可以编写
ConfirmCallback函数 - 消息成功到达交换机后,RabbitMQ会调用
ConfirmCallback通知消息的发送者,返回ACK - 消息如果未到达交换机,RabbitMQ也会调用
ConfirmCallback通知消息的发送者,返回NACK - 消息超时未发送成功也会
抛出异常
- 生产者发送消息后,可以编写
- RabbitMQ提供了
- 消息到达交换机后,如果
未能到达队列,也会导致消息丢失:- RabbitMQ提供了
publisher return机制- 生产者可以定义ReturnCallback函数
- 消息到达交换机,未到达队列,RabbitMQ会调用ReturnCallback通知发送者,告知失败原因
- RabbitMQ提供了
- 消息到达队列后,
MQ宕机也可能导致消息丢失:- RabbitMQ提供了
持久化功能,集群的主从备份功能- 消息持久化,RabbitMQ会将交换机、队列、消息持久化到磁盘,宕机重启可以恢复消息
- 镜像集群,仲裁队列,都可以提供主从备份功能,主节点宕机,从节点会自动切换为主,数据依然在
- RabbitMQ提供了
- 消息投递给消费者后,如果消费者处理不当,也可能导致消息丢失
- SpringAMQP基于RabbitMQ提供了消费者确认机制、消费者重试机制,消费者失败处理策略:
- 消费者的确认机制:
- 消费者处理消息成功,未出现异常时,Spring返回ACK给RabbitMQ,消息才被移除
- 消费者处理消息失败,抛出异常,宕机,Spring返回NACK或者不返回结果,消息不被异常
- 消费者重试机制:
- 默认情况下,消费者处理失败时,消息会再次回到MQ队列,然后投递给其它消费者。Spring提供的消费者重试机制,则是在处理失败后不返回NACK,而是直接在消费者本地重试。多次重试都失败后,则按照消费者失败处理策略来处理消息。避免了消息频繁入队带来的额外压力。
- 消费者失败策略:
- 当消费者多次本地重试失败时,消息默认会丢弃。
- Spring提供了
Republish策略,在多次重试都失败,耗尽重试次数后,将消息重新投递给指定的异常交换机,并且会携带上异常栈信息,帮助定位问题。
- 消费者的确认机制:
- SpringAMQP基于RabbitMQ提供了消费者确认机制、消费者重试机制,消费者失败处理策略:
三、RocketMQ
1. RocketMQ 如何保证高可用性 ?
-
主从机制
消息生产的高可用:创建topic时,把topic的多个message queue创建在多个broker组上。这样当一个broker组的master不可用后,producer仍然可以给其他组的master发送消息。
消息消费的高可用:消费者一般从master上进行消费,当master不可用或者繁忙的时候consumer会被自动切换到从slave读。注意:RocketMQ 是不支持自动主从切换的,当主节点挂掉之后,生产者就不能再给这个主节点生产消息了。
-
刷盘机制
同步刷盘:当数据写如到内存中之后立刻刷盘(同步),在保证刷盘成功的前提下响应client。
异步刷盘:数据写入内存后,直接响应client。异步将内存中的数据持久化到磁盘上。
RocketMQ采用多住多从,同步复制和异步刷盘保证高可用性。 同步复制: 也叫 “同步双写”,也就是说,只有消息同步双写到主从节点上时才返回写入成功 。
异步复制: 消息写入主节点之后就直接返回写入成功 。

2. RocketMQ 的存储机制
CommitLog:消息主体以及元数据的存储主体,存储 Producer 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。
ConsumeQueue:消息消费队列,Consumer 即可根据 ConsumeQueue 来查找待消费的消息。其中,ConsumeQueue作为消费消息的索引,保存了指定 Topic 下的队列消息在 CommitLog 中的起始物理偏移量 offset ,消息大小 size 和消息 Tag 的 HashCode 值。consumequeue 文件可以看成是基于 topic 的 commitlog 索引文件。
IndexFile:IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。
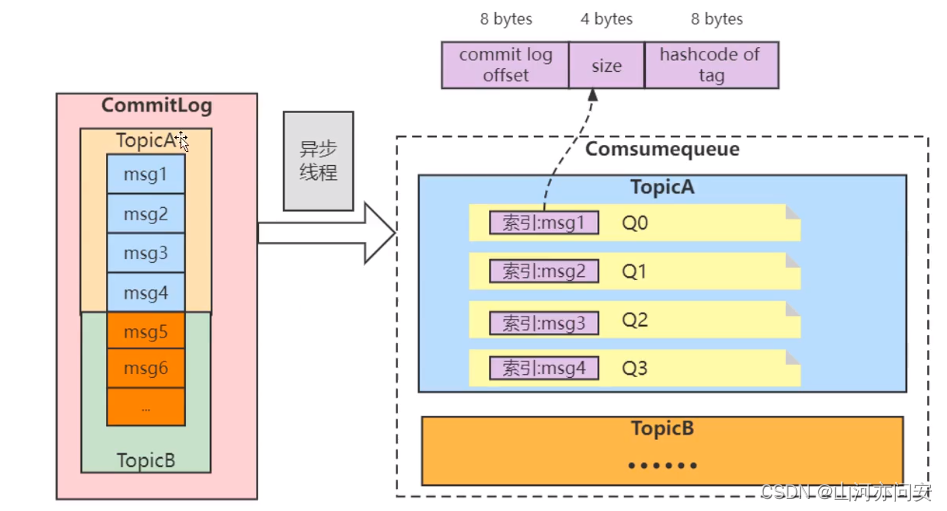
3. RocketMQ 性能比较高的原因 ?
- Netty高效的NIO框架
- 大量使用多线程异步
- 采用零拷贝技术MMAP
- 文件存储顺序读写
- 锁优化CAS机制无锁化
- 存储设计读写分离。